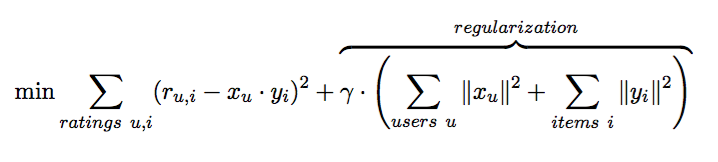Blog containing a database of articles, reports, blogger's notes and photos of Bosnia and Herzegovina and Balkans region. The compilation and material was created by Aleksandra Miletić-Šantić, a lawyer, social scientist, human rights activist, journalist and interpreter.
The Srebrenica report reveals the Pentagon's role in a dirty war
The official Dutch inquiry into the 1995
Srebrenica massacre, released last week, contains one of the most
sensational reports on western intelligence ever published. Officials
have been staggered by its findings and the Dutch government has
resigned. One of its many volumes is devoted to clandestine activities
during the Bosnian war of the early 1990s. For five years, Professor
Cees Wiebes of Amsterdam University has had unrestricted access to Dutch
intelligence files and has stalked the corridors of secret service
headquarters in western capitals, as well as in Bosnia, asking
questions.
His findings are set out in
"Intelligence and the war in Bosnia, 1992-1995". It includes remarkable
material on covert op erations, signals interception, human agents and
double-crossing by dozens of agencies in one of dirtiest wars of the new
world disorder. Now we have the full story of the secret alliance
between the Pentagon and radical Islamist groups from the Middle East
designed to assist the Bosnian Muslims - some of the same groups that
the Pentagon is now fighting in "the war against terrorism". Pentagon
operations in Bosnia have delivered their own "blowback".
In
the 1980s Washington's secret services had assisted Saddam Hussein in
his war against Iran. Then, in 1990, the US fought him in the Gulf. In
both Afghanistan and the Gulf, the Pentagon had incurred debts to
Islamist groups and their Middle Eastern sponsors. By 1993 these groups,
many supported by Iran and Saudi Arabia, were anxious to help Bosnian
Muslims fighting in the former Yugoslavia and called in their debts with
the Americans. Bill Clinton and the Pentagon were keen to be seen as
creditworthy and repaid in the form of an Iran-Contra style operation -
in flagrant violation of the UN security council arms embargo against
all combatants in the former Yugoslavia.
The result was a vast secret conduit of
weapons smuggling though Croatia. This was arranged by the clandestine
agencies of the US, Turkey and Iran, together with a range of radical
Islamist groups, including Afghan mojahedin and the pro-Iranian
Hizbullah. Wiebes reveals that the British intelligence services
obtained documents early on in the Bosnian war proving that Iran was
making direct deliveries.
Arms
purchased by Iran and Turkey with the financial backing of Saudi Arabia
made their way by night from the Middle East. Initially aircraft from
Iran Air were used, but as the volume increased they were joined by a
mysterious fleet of black C-130 Hercules aircraft. The report stresses
that the US was "very closely involved" in the airlift. Mojahedin
fighters were also flown in, but they were reserved as shock troops for
especially hazardous operations.
Light
weapons are the familiar currency of secret services seeking to
influence such conflicts. The volume of weapons flown into Croatia was
enormous, partly because of a steep Croatian "transit tax". Croatian
forces creamed off between 20% and 50% of the arms. The report stresses
that this entire trade was clearly illicit. The Croats themselves also
obtained massive quantities of illegal weapons from Germany, Belgium and
Argentina - again in contravention of the UN arms embargo. The German
secret services were fully aware of the trade.
Rather
than the CIA, the Pentagon's own secret service was the hidden force
behind these operations. The UN protection force, UNPROFOR, was
dependent on its troop-contributing nations for intelligence, and above
all on the sophisticated monitoring capabilities of the US to police the
arms embargo. This gave the Pentagon the ability to manipulate the
embargo at will: ensuring that American Awacs aircraft covered crucial
areas and were able to turn a blind eye to the frequent nightime comings
and goings at Tuzla.
Weapons
flown in during the spring of 1995 were to turn up only a fortnight
later in the besieged and demilitarised enclave at Srebrenica. When
these shipments were noticed, Americans pressured UNPROFOR to rewrite
reports, and when Norwegian officials protested about the flights, they
were reportedly threatened into silence.
Both the CIA and British SIS had a more
sophisticated perspective on the conflict than the Pentagon, insisting
that no side had clean hands and arguing for caution. James Woolsey,
director of the CIA until May 1995, had increasingly found himself out
of step with the Clinton White House over his reluctance to develop
close relations with the Islamists. The sentiments were reciprocated. In
the spring of 1995, when the CIA sent its first head of station to
Sarajevo to liaise with Bosnia's security authorities, the Bosnians
tipped off Iranian intelligence. The CIA learned that the Iranians had
targeted him for liquidation and quickly withdrew him.
Iranian
and Afghan veterans' training camps had also been identified in Bosnia.
Later, in the Dayton Accords of November 1995, the stipulation appeared
that all foreign forces be withdrawn. This was a deliberate attempt to
cleanse Bosnia of Iranian-run training camps. The CIA's main opponents
in Bosnia were now the mojahedin fighters and their Iranian trainers -
whom the Pentagon had been helping to supply months earlier.
Meanwhile, the secret services of
Ukraine, Greece and Israel were busy arming the Bosnian Serbs. Mossad
was especially active and concluded a deal with the Bosnian Serbs at
Pale involving a substantial supply of artillery shells and mortar
bombs. In return they secured safe passage for the Jewish population out
of the besieged town of Sarajevo. Subsequently, the remaining
population was perplexed to find that unexploded mortar bombs landing in
Sarajevo sometimes had Hebrew markings.
The
broader lessons of the intelligence report on Srebrenica are clear.
Those who were able to deploy intelligence power, including the
Americans and their enemies, the Bosnian Serbs, were both able to get
their way. Conversely, the UN and the Dutch government were "deprived of
the means and capacity for obtaining intelligence" for the Srebrenica
deployment, helping to explain why they blundered in, and contributed to
the terrible events there.
Secret intelligence techniques can be
war-winning and life-saving. But they are not being properly applied.
How the UN can have good intelligence in the context of multinational
peace operations is a vexing question. Removing light weapons from a
conflict can be crucial to drawing it down. But the secret services of
some states - including Israel and Iran - continue to be a major source
of covert supply, pouring petrol on the flames of already bitter
conflicts.
· Richard J
Aldrich is Professor of Politics at the University of Nottingham. His
'The Hidden Hand: Britain, America and Cold War Secret Intelligence' is
published in paperback by John Murray in August.
The growth of data on the web has made it harder to employ many
machine learning algorithms on the full data sets. For personalization
problems in particular, where data sampling is often not an option,
innovating on distributed algorithm design is necessary to allow us to
scale to these constantly growing data sets.
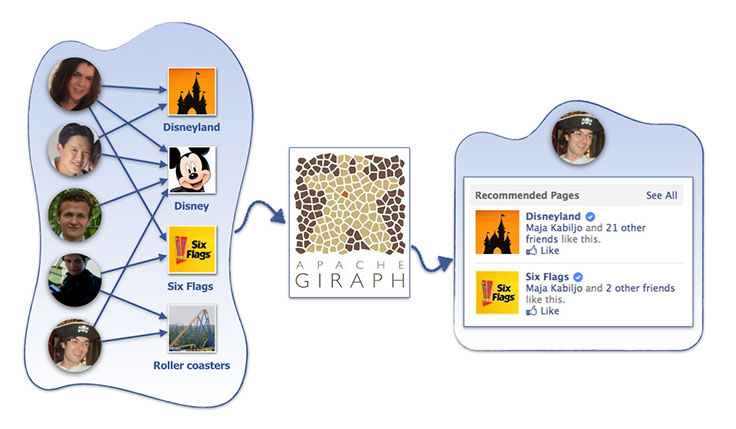
Collaborative filtering (CF) is one of the important areas where this
applies. CF is a recommender systems technique that helps people
discover items that are most relevant to them. At Facebook, this might
include pages, groups, events, games, and more. CF is based on the idea
that the best recommendations come from people who have similar tastes.
In other words, it uses historical item ratings of like-minded people to
predict how someone would rate an item.
CF and Facebook scale
Facebook’s average data set for CF has 100 billion ratings, more than
a billion users, and millions of items. In comparison, the well-known Netflix Prize
recommender competition featured a large-scale industrial data set with
100 million ratings, 480,000 users, and 17,770 movies (items). There
has been more development in the field since then, but still, the
largest numbers we’ve read about are at least two orders of magnitude
smaller than what we’re dealing with.
A challenge we faced is to design a distributed algorithm that is
going to scale to these massive data sets, and how to overcome issues
that arose because of certain properties of our data (like skewed item
degree distribution, or implicit engagement signals instead of ratings).
As we’ll discuss below, approaches used in existing solutions would
not efficiently handle our data sizes. Simply put, we needed a new
solution. We’ve written before about Apache Giraph, a powerful platform
for distributed iterative and graph processing, and the work we put into
making it scale to our needs. We’ve also written about one of the applications we developed
on top of it about graph partitioning. Giraph works extremely well on
massive data sets, it is easily extensible, and we have a lot of
experience in developing highly performant applications on top of it.
Therefore, Giraph was our obvious choice for this problem.
Matrix factorization
A common approach to CF is through matrix factorization, in which we
look at the problem as having a set of users and a set of items, and a
very sparse matrix that represents known user-to-item ratings. We want
to predict missing values in this matrix. In order to do this, we
represent each user and each item as a vector of latent features, such
that dot products of these vectors closely match known user-to-item
ratings. The expectation is that unknown user-to-item ratings can be
approximated by dot products of corresponding feature vectors, as well.
The simplest form of objective function, which we want to minimize, is:
Here, r are known user-to-item ratings, and x and y
are the user and item feature vectors that we are trying to find. As
there are many free parameters, we need the regularization part to
prevent overfitting and numerical problems, with gamma being the
regularization factor.
It is not currently feasible to find the optimal solution of the
above formula in a reasonable time, but there are iterative approaches
that start from random feature vectors and gradually improve the
solution. After some number of iterations, changes in feature vectors
become very small, and convergence is reached. There are two commonly
used iterative approaches.
Stochastic gradient descent optimization
Stochastic gradient descent (SGD) optimization was successfully
practiced in many other problems. The algorithm loops through all
ratings in the training data in a random order, and for each known
rating r, it makes a prediction r* (based on the dot product of vectors x and y) and computes prediction error e. Then we modify x and y by moving them in the opposite direction of the gradient, yielding certain update formulas for each of the features of x and y.
Alternating least square
Alternating least square (ALS) is another method used with nonlinear
regression models, when there are two dependent variables (in our case,
vectors x and y). The algorithm fixes one of the parameters (user vectors x), while optimally solving for the other (item vectors y)
by minimizing the quadratic form. The algorithm alternates between
fixing user vectors and updating item vectors, and fixing item vectors
and updating user vectors, until the convergence criteria are satisfied.
Standard approach and problems
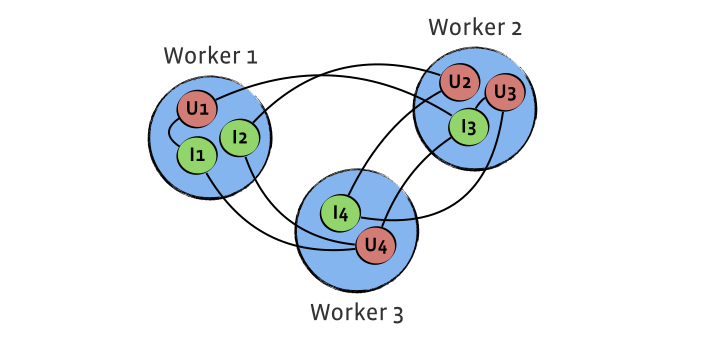
In order to efficiently solve the above formula in a distributed way,
we first looked at how systems that are similar in design to Giraph do
it (using message passing instead of map/reduce). The standard approach
corresponds to having both users and items as vertices of a graph, with
edges representing known ratings. An iteration of SGD/ALS would then
send user and/or item feature vectors across all the edges of the graph
and do local updates.
There are a few problems with this solution:
Huge amount of network traffic: This is the main
bottleneck of all distributed matrix factorization algorithms. Since we
send a feature vector across each edge of the graph, the amount of data
sent over the wire in one iteration is proportional to #Ratings * #Features
(here and later in the text we use # as notation for ‘number of’). For
100 billion ratings and 100 double features, this results in 80 TB of
network traffic per iteration. Here we assumed that users and items are
distributed randomly, and we are ignoring the fact that some of the
ratings can live on the same worker (on average, this should be
multiplied by the factor 1 – (1 / #Workers)). Note that smart
partitioning can’t reduce network traffic by a lot because of the items
that have large degrees, and that would not solve our problem.
Some items in our data sets are very popular, so item degree distribution is highly skewed: This can cause memory problems — every item is receiving degree * #Features
amount of data. For example, if an item has 100 million known ratings
and 100 double features are used, this item alone would receive 80 GB of
data. Large-degree items also cause processing bottlenecks (as every
vertex is atomically processed), and everyone will wait for a few
largest-degree items to be finished.
This does not implement SGD exactly in the original formulation:
Every vertex is working with feature vectors that it received in the
beginning of the iteration, instead of the latest version of them. For
example, say item A has ratings for users B and C. In a sequential
solution, we’d update A and B first, getting A’ and B’, and then update
A’ and C. With this solution, both B and C will be updated with A, the
feature vector for the item from the beginning of the iteration. (This
is practiced with some lock-free parallel execution algorithms and can
slow down the convergence.)
Our solution — rotational hybrid approach
The main problem is sending all updates within each iteration, so we
needed a new technique of combining these updates and sending less data.
First we tried to leverage aggregators
and use them to distribute item data, but none of the formulas we tried
for combining partial updates on the item feature vectors worked well.
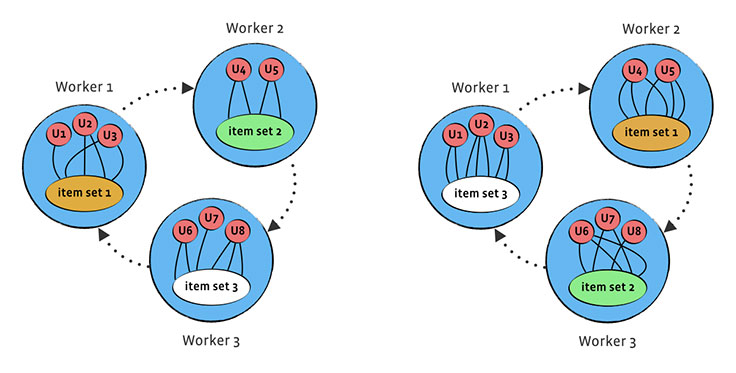
We finally came up with an approach that required us to extend Giraph
framework with worker-to-worker messaging. Users are still presented as
the vertices of the graph, but items are partitioned in #Workers
disjoint parts, with each of these parts stored in global data of one
of the workers. We put all workers in a circle, and rotate the items in
clockwise direction after each superstep, by sending worker-to-worker
messages containing items from each worker to the next worker in the
line.
This way, in each superstep, we process part of the worker’s user
ratings for the items that are currently on the worker, and therefore
process all ratings after #Workers supersteps. Let’s analyze the issues the previous solutions had:
Amount of network traffic: For SGD, the amount of data sent over the wire in one iteration is proportional to #Items * #Features * #Workers,
and it doesn’t depend on the number of known ratings anymore. For 10
million items, 100 double features, and 50 workers, this brings a total
of 400 GB, which is 20x smaller than in the standard approach.
Therefore, for #Workers <= #Ratings / #Items rotational
approach performs much better, i.e., if the number of workers is less
than the average item degree. In all data sets that we are using, the
items with small degree are ignored from consideration, as those do not
represent good recommendations and can be just noise, so average item
degree is large. We’ll talk below more about ALS.
Skewed item degrees: This is no longer a problem —
user vertices are the only ones doing processing, and items never hold
information about their user ratings.
Computation of SGD: This is equal as in a
sequential solution, because there is only one version of a feature
vector at any point of time, instead of having copies of them sent to
many workers and doing updates based on that.
The computation with ALS is trickier than with SGD, because in order
to update a user/item, we need all its item/user feature vectors. The
way updates in ALS actually go is that we are solving a matrix equation
of type A * X = B, where A is #Features x #Features matrix and B is 1 x #Features vector, and A and B
are calculated based on user/item feature vectors forming all known
ratings for item/user. So when updating items, instead of rotating just
their feature vectors, we can rotate A and B, update them during each of #Workers supersteps and calculate new feature vectors in the end. This increases the amount of network traffic to #Items * #Features2 * #Workers.
Depending on proportions between all the data dimensions, for some
items this is better than the standard approach, and for some it isn’t.
This is why a blend of our rotational approach and the standard
approach gives the superior solution. By looking at item with some
degree, in the standard approach the amount of network traffic
associated with it is degree * #Features, and with our rotational approach, it’s #Workers * #Features2. We’ll still update items in which degree < #Workers * #Features
using the standard approach, and we’ll use our rotational approach for
all larger-degree items, and therefore significantly improve
performance. For example, for 100 double features and 50 workers, the
item degree limit for choosing an approach is around 5,000.
To solve the matrix equation A * X = B we need to find the inverse A-1, for which we use open source library JBLAS, which had the most efficient implementation for the matrix inverse.
As SGD and ALS share the same optimization formula, it is also
possible to combine these algorithms. ALS is computationally more
complex than SGD, and we included an option to do a combination of some
number of iterations of SGD, followed by a single iteration of ALS. For
some data sets, this was shown to help in the offline metrics (e.g.,
root mean squared error or mean average rank).
We were experiencing numerical issues with large-degree items. There
are several ways of bypassing this problem (ignoring these items or
sample them), but we were using regularization based on the item and
user degrees. That keeps the values for user and item vectors in a
certain numerical range.
Evaluation data and parameters
In order to measure the quality of recommendations, before running an
actual A/B test, we can use a sample of the existing data to compute
some offline metrics about how different our estimations are from the
actual user preferences. Both of the above algorithms have a lot of
hyperparameters to tune via cross-validation in order to get the best
recommendations, and we provide other options like adding user and item
biases.
The input ratings can be split in two data sets (train and test)
explicitly. This can be very useful in cases in which testing data is
composed of all user actions in the time interval after all training
instances. Otherwise, to construct the test data, we randomly selected
T=1 items per user, and keep them apart from training.
During the algorithm, for a certain percent of users we rank all
unrated items (i.e., items that are not in the training set) and observe
where training and testing items are in the ranked list of
recommendations. Then we can evaluate the following metrics: mean
average rank (the position in the ranked list, averaged over all test
items), precision at positions 1/10/100, mean of the average precision
across all test items (MAP), etc. Additionally we compute root mean
squared error (RMSE), which amplifies the contributions of the absolute
errors between the predictions and the true values. To help monitor
convergence and quality of results, after each iteration we are printing
all these metrics.
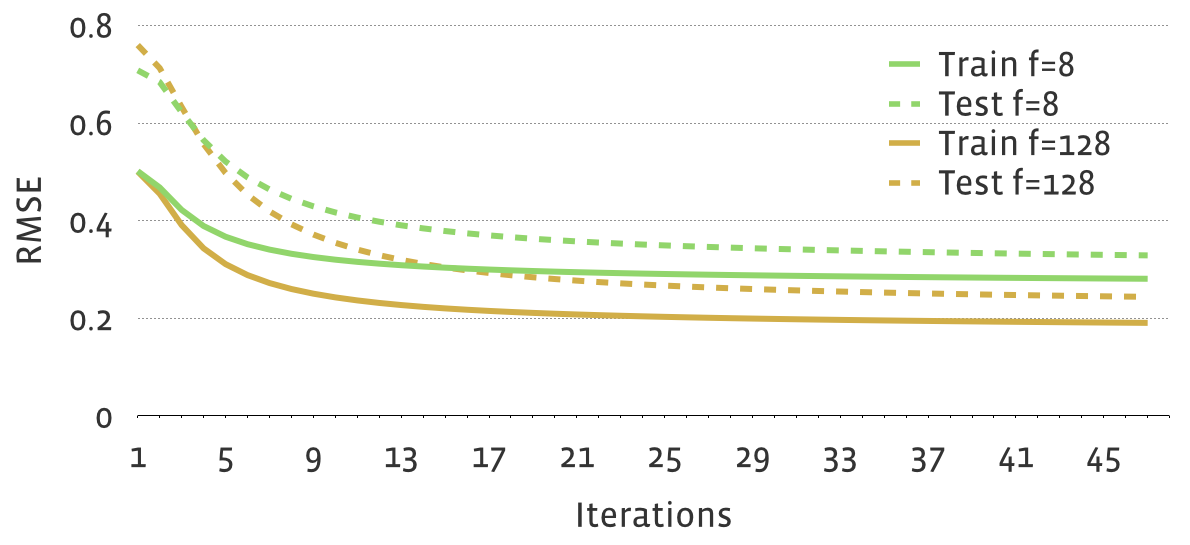
On a sample data set with 35 billion weighted training ratings and
0.2 billion testing ratings, the following figure shows how RMSE reduces
on training and testing sets for #Features=8 or #Features=128, where other parameters are fixed.
Item recommendation computation
In order to get the actual recommendations for all users, we need to
find items with highest predicted ratings for each user. When dealing
with the huge data sets, checking the dot product for each (user, item)
pair becomes unfeasible, even if we distribute the problem to more
workers. We needed a faster way to find the top K recommendations for
each user, or a good approximation of it.
One possible solution is to use a ball tree
data structure to hold our item vectors. A ball tree is a binary tree
where leafs contain some subset of item vectors, and each inner node
defines a ball that surrounds all vectors within its subtree. Using
formulas for the upper bound on the dot product for the query vector and
any vector within the ball, we can do greedy tree traversal, going
first to the more promising branch, and prune subtrees that can’t
contain the solution better than what we have already found. This
approach showed to be 10-100x faster than looking into each pair, making
search for recommendations on our data sets finish in reasonable time.
We also added an option to allow for specified error when looking for
top recommendations to speed up calculations even more.
Another way the problem can be approximately solved is by clustering
items based on the item feature vectors — which reduces the problem to
finding top cluster recommendations and then extracting the actual items
based on these top clusters. This approach speeds up the computation,
while slightly degrading the quality of recommendations based on the
experimental results. On the other hand, the items in a cluster are
similar, and we can get a diverse set of recommendations by taking a
limited number of the items from each cluster. Note that we also have
k-means clustering implementation on top of Giraph, and incorporating
this step in the calculation was very easy.
Comparison with MLlib
Spark MLlib
is a very popular machine-learning library that contains one of the
leading open source implementations in this domain. In July 2014, the
Databricks team published performance numbers of their ALS implementation on Spark. Experiments were conducted on scaled copies of the Amazon reviews data set, which originally contained 35 million ratings and ran for five iterations.
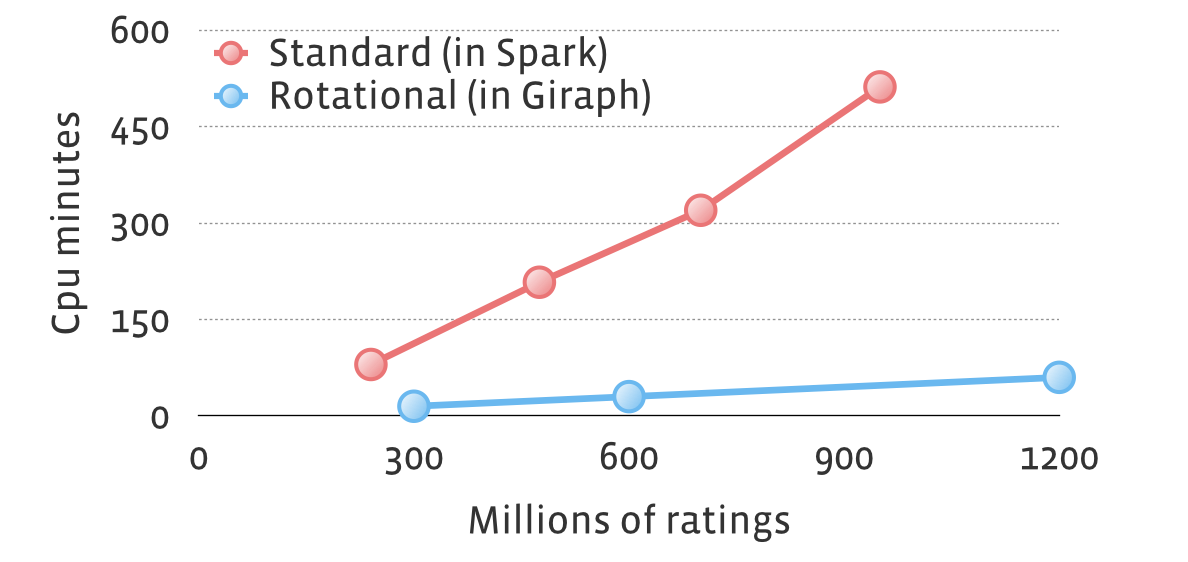
In the following graph, we compared our rotational hybrid approach
(which we implemented in Giraph) with the standard approach (implemented
in Spark MLlib, including some additional optimizations, like sending a
feature vector at most once to a machine), on the same data set. Due to
hardware differences (we had about twice the processing power per
machine), in order to make a fair comparison we were looking at total
CPU minutes. Rotational hybrid solution was about 10x faster.
Additionally, the largest data set on which experiments were
conducted with standard approach had 3.5 billion ratings. With
rotational hybrid approach, we can easily handle more than 100 billion
ratings. Note that quality of results is the same for both, and all
performance and scalability gains come from different data layout and
decreased network traffic.
Facebook use cases and implicit feedback
We used this algorithm for multiple applications at Facebook, e.g.
for recommending pages you might like or groups you should join. As
already mentioned, our data sets are composed of more than 1 billion
users and usually tens of millions of items. There are actually many
more pages or groups, but we limit ourselves to items that pass a
certain quality threshold — where the simplest version is to have the
item degree greater than 100. (Fun side note: On the other side, we have
some very large-degree pages — the “Facebook for Every Phone” page is actually liked by almost half of Facebook’s current monthly active users.)
Our first iterations included page likes/group joins as positive
signals. The negative signals on Facebook are not as common (negative
signals include unliking a page or leaving a group after some time).
Also this may not actually mean that a user has negative feedback for
that item; instead, he or she might have lost interest in the topic or
in receiving updates. In order to get good recommendations, there is a
significant need for adding negative items from the unrated pairs in the
collection. Previous approaches include randomly picking negative
training sample from unrated items (leading to a biased, non-optimal
solution) or treating all unknown ratings as negative, which
tremendously increases complexity of the algorithm. Here, we implemented
adding random negative ratings by taking into account the user and item
degrees (adding negative ratings proportional to the user degree based
on the item degree distribution), and weighing negative ratings less
than positive ones, as we failed to learn a good model with uniform
random sampling approach.
On the other hand, we have implicit feedback from users (whether the
user is actively viewing the page, liking, or commenting on the posts in
the group). We also implemented a well-known ALS-based algorithm for
implicit feedback data sets. Instead of trying to model the matrix of
ratings directly, this approach treats the data as a combination of
binary preferences and confidence values. The ratings are then related
to the level of confidence in observed user preferences, rather than
explicit ratings given to items.
After running the matrix factorization algorithm, we have another
Giraph job of actually computing top recommendations for all users.
The following code just shows how easy it is to use our framework, tune parameters, and plug in different data sets:
Furthermore, one can simply implement other objective functions (such
as rank optimizations or neighboring models) by extending SGD or ALS
computation.
Scalable CF
Recommendation systems are emerging as important tools for predicting
user preferences. Our framework for matrix factorization and computing
top user recommendations is able to efficiently handle Facebook’s
massive data sets with 100 billion ratings. It is easy to use and extend
with other approaches.
We are thinking about many improvements and algorithms, including:
Incorporating the social graph and user connections for providing a better set of recommendations
Starting from the previous models instead of random initialization, for recurrent learning
Automatic parameter fitting with cross-validation for optimizing the different metrics for a given data set
Trying out better partitioning and skipping machines that don’t need certain item data during rotations
We are actively working on recommendations and many other
applications on top of Giraph, so stay tuned for more exciting features
and development in this field.
Thanks to Dionysios Logothetis, Avery Ching, Sambavi Muthukrishnan
and Sergey Edunov from the Giraph team who made this work possible and
helped write this story, and Liang Xiong and Bradley Green for early
experimentation and all feedback and insights.
Facebook uses machine learning and ranking models to deliver the
best experiences across many different parts of the app, such as which
notifications to send, which stories you see in News Feed, or which
recommendations you get for Pages you might want to follow. To surface
the most relevant content, it’s important to have high-quality machine
learning models. We look at a number of real-time signals to determine
optimal ranking; for example, in the notifications filtering use case,
we look at whether someone has already clicked on similar notifications
or how many likes the story corresponding to a notification has gotten.
Because we perform this every time a new notification is generated, we
want to return the decision for sending notifications as quickly as
possible.
More complex models can help improve the precision of our predictions
and show more relevant content, but the trade-off is that they require
more CPU cycles and can take longer to return results. Given these
constraints, we can’t always evaluate all possible candidates. However,
by improving the efficiency of the model, we can evaluate more inventory
in the same time frame and with the same computing resources.
In this post, we compare different implementations of a type of
predictive model called a gradient-boosted decision tree (GBDT) and
describe multiple improvements in C++ that resulted in more efficient
evaluations.
Decision tree models
Decision trees are commonly used as a predictive model, mapping
observations about an item to conclusions about the item’s target value.
It is one of the most common predictive modeling approaches used in
machine learning, data analysis, and statistics due to its non-linearity
and fast evaluation. In these tree structures, leaves represent class
labels and branches represent conjunctions of features that lead to
those class labels.
Decision trees are very powerful, but a small change in the training
data can produce a big change in the tree. This is remedied by the use
of a technique called gradient boosting.
Namely, the training examples that were misclassified have their
weights boosted, and a new tree is formed. This procedure is then
repeated consecutively for the new trees. The final score is taken as a
weighted sum of the scores of the individual leaves from all trees.
Models are normally updated infrequently, and training complex models
can take hours. At Facebook’s scale, however, we want to update the
models more often and run them on the order of milliseconds. Many
backend services at Facebook are written in C++, so we leveraged some of
the properties of this language and made improvements that resulted in a
more efficient model that takes fewer CPU cycles to evaluate.
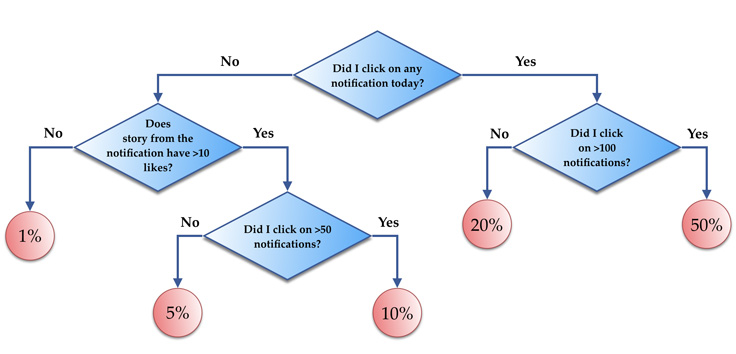
In the next figure we have a simple decision tree with the following features:
the number of clicks on notifications from person A today (feature F[0])
the number of likes on the story corresponding to the notification (feature F[1])
the total number of notification clicks from person A (feature F[2])
At different nodes, we check the values of the above features and
traverse the tree to get the probability of clicking on a notification.
Flat tree implementation
The naive implementation of the decision tree model is a simple binary tree
with pointers. However, this is not very efficient due to the fact that
the nodes do not need to be stored consecutively in the memory.
On the other hand, decision trees are usually full binary trees (a
binary tree in which each node has exactly zero or two children) and can
be stored compactly using vectors. No space is required for the
pointer; instead, the parent and children of each node can be found by
arithmetic on array indices. We will use this implementation for
comparison in the experimentation section.
Compiled tree implementation
Each binary tree can be represented as a complex ternary expression,
which can be compiled and linked to a dynamic library (DLL) that can be
directly used in the service. Note that we can add or update the
decision tree model in real time without restarting the service.
We can also take advantage of LIKELY/UNLIKELY annotations in C++.
They are directions for the compiler to emit instructions that will
cause branch prediction to favor the “likely” side of a jump
instruction. If the prediction is correct, it means that the jump
instruction will take zero CPU cycles. We can compute branch predictions
based on the real samples from the ranking in batches or from the
offline analysis, as the distributions from training and evaluation sets
should not change much.
The following code represents an implementation of the above simiple decision tree:
In a typical ranking setup, we need to evaluate the same trained
model on multiple instances of feature vectors. For example, we need to
rank ~1,000 different potential candidates for a given person, and pick
only the most relevant ones.
One approach is to iterate through all candidates and rank them one
by one. Typically, the model and all candidates cannot fit together into
the CPU instruction cache. Motivated by the boosted training, we can
actually split the model into ranges of trees (the first N trees, then
the next N trees, and so on), so that each range will be small enough to
fit the cache memory. Then we can flip the evaluation order: Instead of
evaluating all trees on a sample, we will evaluate all samples on each
range. This way we can fit the whole tree set in the CPU cache together
with all feature vectors, and in the next iteration just replace the
tree set. This reduces the number of cache misses and uses block
reads/writes instead of RAM.
Furthermore, we often have multiple models that we need to evaluate
on the same feature vectors; for example, the probability of the user
clicking, liking, or commenting on the notification story. This helps
keep all feature vectors in the CPU cache and evaluating models one by
one.
Another trade-off that we can make is to rank all candidates for the
first N trees and then, due to the nature of boosted algorithms, discard
the lowest-ranked candidates. This can improve the latency, but it
comes with a slight drop in accuracy.
Common features
Sometimes features are common across all feature vectors. In the
above example for a certain person, we need to rank all candidate
notifications. The feature vectors [F[0], F[1], F[2]] described above
can be something like this:
[0, 2, 100]
[0, 0, 100]
[0, 1, 100]
[0, 1, 100]
It’s easily noticeable that the features F[0] and F[2] are the same
for candidates. We can significantly reduce the decision tree size by
just focusing on the value F[1], and thus improve the evaluation time.
Categorical features
Most ML algorithms use binary trees, and this can be extended to
k-ary trees. On the other hand, some of the features are not actually
comparable and are called categorical features. For example, if country
is a feature, one cannot say whether the value is less than or equal to
“US” (or a corresponding enum value). If the tree is deep enough, this
comparison can be achieved using multiple levels, but here we
implemented the possibility for checking whether the current feature
belongs to a set of values.
The learning method is not changed much — we still try to find the
best subset to split on, and the evaluation is very fast. Based on the
size of the set, we use the in_set C++ implementation or just concatenate if conditions. This reduces the model size and helps in convergence as well.
Computational results
We trained a boosted decision tree model for predicting the
probability of clicking a notification using 256 trees, where each of
the trees contains 32 leaves. Next, we compared the CPU usage for
feature vector evaluations, where each batch was ranking 1,000
candidates on average. The batch size value N was tuned to be optimal
based on the machine L1/L2 cache sizes. We saw the following performance
improvements over the flat tree implementation:
Plain compiled model: 2x improvement.
Compiled model with annotations: 2.5x improvement.
Compiled model with annotations, ranges and common/categorical features: 5x improvement.
The performance improvements were similar for different algorithm parameters (128 or 512 trees, 16 or 64 leaves).
Conclusion
These improvements in CPU usage and resulting speedups allowed us to
increase the number of examples we rank or increase the model size using
the same amount of resources. This approach has been applied to several
ranking models at Facebook, including notifications filtering, feed
ranking, and suggestions for people and Pages to follow. Our machine
learning platforms are constantly evolving; more precise models combined
with more efficient model evaluations will allow us to continually
improve our ranking systems to serve the best personalized experiences
for billions of people.
Mountain View, California, United States500+ connections
About
- Privacy lead for cross account data sharing - Leading
Identity Platform team of 50+ people for the Facebook Family of Apps
(Facebook, Instagram, WhatsApp, Oculus) with product applications in
Growth, Ads, Analytics, Integrity. - Built notifications system team at Facebook for targeting and optimizing notifications sending via push, SMS and email -
Senior researcher in the spectral and chemical graph theory,
combinatorics, algorithms and social networks (over 100 publications
https://scholar.google.com/citations?user=qnL0jnwAAAAJ&hl=en)
- Company privacy lead for cross app data sharing - Leading
Identity Platform team of 50+ people for the Facebook Family of Apps
with applications on Growth, Ads, Accounting, Integrity. - Previously
team lead (20+ people) on Notifications system used by all teams at
Facebook for targeting and optimizing notifications sending via push,
SMS, email - Previously part of Facebook growth team and responsible for adding 20+ million of incremental MAP and DAP users - Designed multiple large…
Working on:
hot list aggregation and distribution, web pages category
classification, topics summary generation, user clustering.
Assistant Professor
Faculty of Sciences and Mathematics, University of Nis
- 3 years 1 month
Courses: Parallel and concurent programming, Introduction to informatics, Design and analysis of algorithms, Introduction to graph theory and combinatorics, Discrete structures
SARAJEVO - Najveći izdavač u BiH "Avaz"
najavio je u petak tužbu protiv OHR-a uz odštetni zahtjev od 50 miliona
evra poslije razotkrivanja, kako tvrde, montiranih šema u kojima se
politički i vjerski vrh bošnjačke vlasti kao i neki biznismeni u FBiH
kvalifikuju kao kriminalna mreža, prenose agencije.
- Zbog nedopustivog i ničim argumentovanog pokušaja rušenja
poslovnog kredibiliteta kompanije, "Avaz" će podnijeti krivičnu prijavu
protiv zamjenika visokog predstavnika u BiH američkog diplomate Rafija
Gregorijana i nepoznatog službenika OHR-a koji se zove Erik i označen je
kao autor sporne šeme - navodi se u saopštenju.
Njih dvojica su, smatraju u sarajevskoj medijskoj kući, na
"kriminalan način teško zloupotrijebili svoje funkcije i mandat OHR-a".
Dodaju da će za ovaj sudski spor kompanija "Avaz" angažovati referentne advokatske kancelarije u Vašingtonu i u Evropi.
Nedjeljnik "Global", koji je izdanje "Avaza", objavio je u
posljednjem broju šeme, koje su navodno napravljene u OHR-u, a kojima se
prikazuje dio političko-kriminalne mreže u Federaciji BiH.
Kao vođe mreže označeni su reis Mustafa Cerić, Hasan Čengić, Fahrudin
Radončić, Bakir Izetbegović, Alija Delimustafića, Bakir Alispahić i
Senad Šahinpašić Šaja.
OHR
Portparol OHR-a Ljiljana Radetić izjavila je "Glasu Srpske" da su
"magazin 'Global' od 29. oktobra i dnevne novine 'Avaz' od 30. oktobra
objavili priče koje su zasnovali na papirima koje su javno povezali sa
Kancelarijom visokog predstavnika".
- Ono što su objavili izgleda kao grafički prikaz izvještavanja iz
javnih izvora kroz nekoliko posljednjih godina. Visoki predstavnik
duboko i iskreno žali zbog bilo kakve neugodnosti ili neprijatnosti
izazvane objavljivanjem ovih članaka - kaže Radetićeva.
Vlada/r/ KS iz sjene: Konakoviću prebacili 325 hiljada maraka za dodjelu grantova
Novac
namijenjen za školovanje policajaca, Vlada KS 12. septembra stavila na
raspolaganje predsjedavajućem Skupštine da bi on mogao dodijeliti grant
Zukorlićevom BANU-u. Ministarstva policije, privrede i finansija odrekla
se sredstava u korist Kabineta Elmedina Konakovića
Vlada Kantona Sarajevo prebacila je najmanje 325 hiljada maraka
namjenskih sredstava na Kabinet predsjedavajućeg Skupštine KS koje je Elmedin Konaković kasnije, kao grantove, proizvoljno dodjeljivao uduženjima bliskim svojoj političkoj partiji.
Samo
u septembru ove godine Vlada je izvršila "preraspodjelu" 95 hiljada
maraka, dok je u avgustu Konakovićev kabinet "pojačan" sa 100 hiljada
maraka.
U junu je vladaru Kantona Sarajevo prebačeno 80 hiljada
maraka, dok je na martovskoj sjednici na Kabinet predsjedavajućeg
Skupštine KS preraspoređeno 50 hiljada maraka. Tako su tim
preraspodjelama, između ostalog, sredstva namijenjena za školovanje
mladih policajaca završila na "razdjelu" predjedavajućeg Skupštine
Kantona Sarajevo kako bi on taj novac mogao odobriti "neprofitnim
organizacijama".
"Odobrava se preraspodjela sredstava u
Budžetu Kantona Sarajevo za 2019. godinu u iznosu od 60 hiljada maraka i
to: sa razdjela 17 Ministarstvo unutrašnjih poslova Kantona Sarajevo,
glava 02, potrošačka jedinica 0001 - Uprava policije, sa ekonomskog koda
- izdaci za školovanje na policijskoj akademiji, na razdjel 10
Skupštine KS, poslanici i parlamentarne grupe, glava 03, potrošačka
jedinica 0001 - Kabinet predsjedavajućeg i zamjenika predsjedavajućeg
Skupštine KS na ekonomski kod: kapitalni transferi neprofitnim
organizacijama", navedeno je u Zaključku Vlade KS usvojenom 12.
septembra 2019. godine, objavljenom u posljednjem broju Službenih
novina Kantona Sarajevo.
Ovaj iznos identičan je iznosu koji je Elmedin Konaković donirao
Bošnjačkoj akademiji nauka i umjetnosti iza koje stoji novopazarski
muftija i ideolog Naroda i pravde - Muamer Zukorlić.
"Izdaci
za obaveze po kreditima - kamata na domaća pozajmljivanja", pisalo je
iza ekonomskog koda sa kojeg je 27. juna ove godine Vlada KS skinula 80
hiljada maraka. Novac je transferisan na Kabinet predsjedavajućeg i
zamjenika predsjedavajućeg Skupštine KS. U odluci objavljenoj u
Službenim novinama KS nije navedeno kako će predsjedavajući Skupštine KS
utrošiti ovaj novac.
Zaključkom Vlade KS od 29. 3. 2019.
godine novac koji se nalazio na računu Ministarstva privrede KS i koji
je planiran za podršku "projektima Privredne komore KS, Obrtničke komore
KS i Udruženju poslodavaca KS", transferisan je prema Kabinetu
predsjedavajućeg Skupštine KS. Šef Skupštine je, potom, tih 50 hiljada
maraka transferisao neprofitnim organizacijama.
Ono što je posebno interesantno je zaključak od 1. avgusta ove
godine. Prema Budžetu KS, Ministarstvo prostornog uređenja KS planiralo
je izdvajaje 100 hiljada KM za "rekontrukciju, adaptaciju, sanaciju, i
izgradnju vjerskih objekata i kulturno historijskih objekata". Taj novac
je, međutim, transferisan na Kabinet predsjedavajućeg i zamjenika
predsjedavajućeg Skupštine KS i to za iste namjene. Dakle, umjesto Vlade
Kantona Sarajevo, novac za vjerske objekte dodjeljivao je Elmedin
Konaković. Sve zaključke potpisao je premijer Kantona Sarajevo - Edin Forto.
Premijer
Kantona Sarajevo, Elmedin Konaković poručio da satnica, koju traže
štrajkači, nikako ne može iznositi 2,75 KM. Smatra da su se troškovi
života u KS-u smanjivali, te da nije bilo zakonske obaveze da se
usklađuje plata. Zdravstveni radnici Kantona Sarajevo su u štrajku od
13. oktobra. Trenutna satnica u KS za zdravstvene radnike je 2,31 KM, a
rade 37,5 sati sedmično. Posljednje usklađivanje satnice je napravljeno
15. aprila 2008. godine..
(FENA)
Premijer
Kantona Sarajevo Elmedin Konaković najavio je da će danas održati
sastanak sa predstavnicima Sindikata radnika zdravstva KS-a kako bi
usaglasili stavove oko okončanja štrajka.
Konaković je kazao za Fenu da je
rebalansom budžeta, koji će se pred zastupnicima Skupštine KS-a naći
krajem oktobra, previđeno da se šest miliona KM izdvoji za nabavku
opreme, kako bi izdvojenih 15 miliona trošili na plaće.
Poručio je da satnica, koju traže štrajkači, nikako ne može iznositi 2,75 KM.
"Za 40 sati rada sedmično, to
bi na mjesečnom nivou iznosilo povećanje od 40.560.000 KM, dok za 37,5
sati 29.650.000 KM i to su novci koje ova Vlada nema. Do izbora bi mogli
isplaćivati te plate, ali bi sistem nakon toga krahirao", naglasio je Konaković.
Izrazio je želju da zdravstveni ranici
imaju najbolje plate u regionu, jer su najbolji, ali da je nemoguće u
godinu dana riješiti sve probleme koji se gomilaju u zdravstvu.
"Bio sam iznenađen činjenicom
da imamo čak 15 miliona za povećanje plaća, ali to je bilo malo ili
nedovoljno ljudima koji vode jedan od ovih sindikata i napravili su taj
štrajk za koji mislim da ne donosi ništa dobro ni nama ni pacijentima", kazao je.
Dodao je da je predstavnike sindikata
pozivao više puta da zajedno pregledaju prihode i rashode u zdravstvu,
ali da još nisu postigli to.
"Komisije i visoke plate su
završena priča, jer je Vlada KS-a to već stavila pod kontrolu i ne
postoji ni jedan aktuelan razlog za štrajk", ocijenio je Konaković.
Smatra da su se troškovi života u KS-u
smanjivali, te da nije bilo zakonske obaveze da se usklađuje plata, što
štrajkači također prigovaraju.